Atypicality Presentation Recap
Yesterday, I gave a presentation introducing the ideas of atypicality to the Monteleoni research group. These are the slides and handwritten notes. I plan to explore this idea further and write up better LaTeX notes, which I will then share as well. For now, the idea of atypicality centers around using two coders: one trained to perform best on typical data and one that is universal and not data specific. A sequence is atypical if its code length using the typical coder is longer than the universal coder, i.e. it is not favored by the typical coder indicating the information is somehow unique.
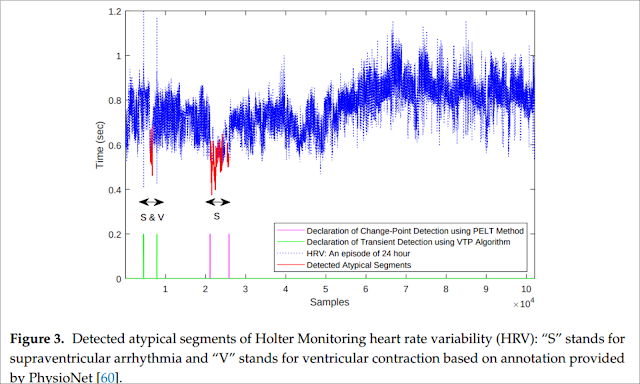
An example of the usage of atypicality from their 2019 paper “Data Discovery and Anomaly Detection using Atypicality for Real-valued data.”
I presented on Elyas Sabeti and Anders H⊘st-Madsen’s 2016 paper titled “How interesting images are: An atypicality approach for social networks”. I think there are lots of opportunities for development in the image space, e.g. using different representations of images maybe including deep learning, exploring what made those images interesting by training a supervised classifier on the resulting labels and exploring the learned features. I’m concerned that their atypicality could be keying on background features, a lot more investigation is needed to understand the details of this application. I also think the image application needs more rigorous validation. They could have tested against other kinds of images to see if they also were labeled as atypical. One idea that was suggested by a member of our group (Amit Rege) is using the atypicality idea in a down-stream application to speed up stochastic gradient descent by picking atypical examples to learn from.
A list of atypicality papers, by Sabeti & H⊘st-Madsen:
- Information theory for atypical sequences (2013)
- Data discovery and anomaly detection using atypicality: theory (2017)
- Atypicality for vector gaussian models (2015)
- Atypicality for the class of exponential family (2016)
- Enhanced MDL with application to atypicality (2017)
- Atypicality for Heart Rate Variability using a pattern-tree weighting method (2017)
- Data Discovery and Anomaly Detection using Atypicality for Real-Valued Data (2019)
comments powered by Disqus